The 1st BlackSwan Challenge
Evaluating Abductive and Defeasible Reasoning in Unpredictable Events
Overview
We feature the BlackSwan Challenge based on our dataset presented at CVPR 2025, which measures deeper reasoning abilities of VLMs in unforeseen and unexpected scenarios.
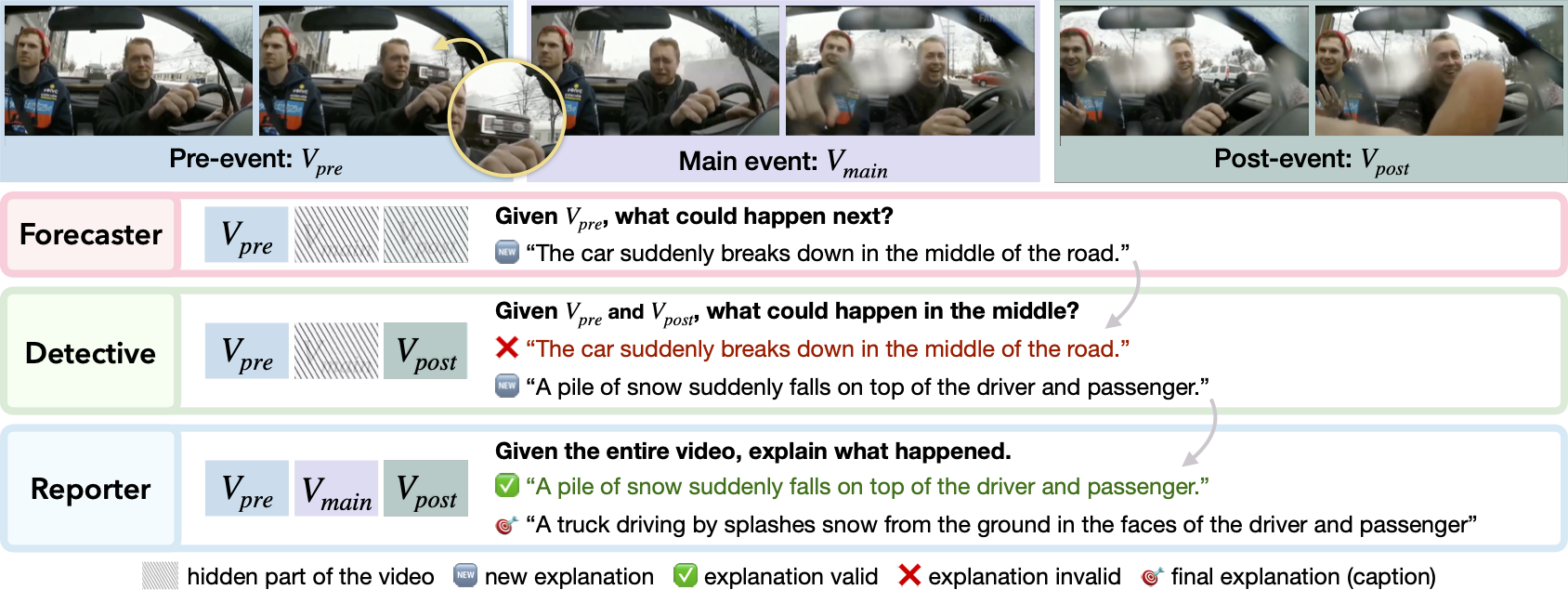
The BlackSwan dataset features three tasks: Forecaster (evaluating what happens next), Detective (testing abductive reasoning) and Reporter (testing defeasible reasoning). Our challenge tests Video-VLMs capabilities at these challenging tasks on unexpected and surprising events in videos.
Challenge Timeline
- February 2026 — The BlackSwan Challenge is now open! See the submission instructions page for details on how to participate.
-
April 15, 2026→ May 1, 2026 (AoE) - Challenge end date
Background
The BlackSwan Challenge arises from the need to rigorously evaluate the abductive and defeasible reasoning capabilities of modern vision-language models (VLMs) in video understanding. While large-scale multimodal models have achieved impressive performance on typical visual reasoning benchmarks, often excelling at describing and interpreting everyday events, their reasoning is frequently correlational rather than cognitive. Existing datasets overwhelmingly emphasize common, well-structured scenarios, leaving it unclear whether VLMs genuinely infer causal explanations or merely rely on memorized statistical patterns.
In contrast, reasoning about unexpected or out-of-distribution events (the "black swan" events of the real world) requires models to move beyond perception and recall, and employ higher-order cognitive reasoning processes. In humans, such reasoning involves abduction (inferring the most plausible hidden cause behind an observation) and defeasibility (updating one's hypothesis when new, conflicting evidence appears). Building models with these abilities is essential for robust, human-like understanding of dynamic real-world environments.
The Challenge
We introduce the BlackSwan Challenge, built upon the recently developed BlackSwanSuite benchmark presented at CVPR 2025. The benchmark evaluates how well VLMs can reason about unexpected events in videos through various tasks, including multiple-choice questions (MCQ). The challenge targets distinct reasoning skills:
Abductive Reasoning
Tasks probe models' ability to infer hidden or missing causes behind surprising events when only partial visual information is provided.
Defeasible Reasoning
Tasks assess whether models can revise their previous conclusions when presented with new evidence that contradicts their earlier assumptions.
The dataset comprises over 3,800 MCQ tasks across 1,655 videos, each containing atypical, counterintuitive, or unexpected visual situations. These scenarios are deliberately constructed to minimize the usefulness of memorized patterns, forcing models to reason instead of recall. BlackSwan is challenging for VLMs, with significant performance gaps of up to 32% from humans on these tasks.
Your goal is to beat existing video understanding models on the BlackSwan MCQ tasks for the Detective and Reporter variants of the benchmark. Submissions are evaluated on MCQ tasks only. Email your predictions to the organizers at cogvl2026@googlegroups.com to receive your scores. The best performing teams will be invited to present their methods at the workshop. See the Submission Details page for full instructions.
Evaluation
The BlackSwan Challenge evaluates submissions on the MCQ task only, using accuracy as the metric. The dataset is split into a public validation set (with ground-truth labels) and a private test set (labels hidden). Participants develop their models on the validation set and submit final predictions for the test set.
We report overall accuracy as well as Detective and Reporter sub-scores to distinguish abductive from defeasible reasoning performance. Videos are provided under the Creative Commons Attribution Non Commercial Share Alike 4.0 license.
Submissions are made by emailing a JSON predictions file to cogvl2026@googlegroups.com. The organizers will evaluate your file against the hidden test labels and reply with your scores. See the Submission Details page for the exact JSON format and email instructions.